

一、什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索(从外部知识库获取信息)和生成(基于检索结果生成回答)的技术,可以提升生成模型(如GPT)的准确性、时效性和可解释性。点此进入ChatWiki体验交流群,免费使用
它通过动态引入外部知识,弥补传统生成模型依赖静态训练数据、易产生“幻觉”的缺陷。
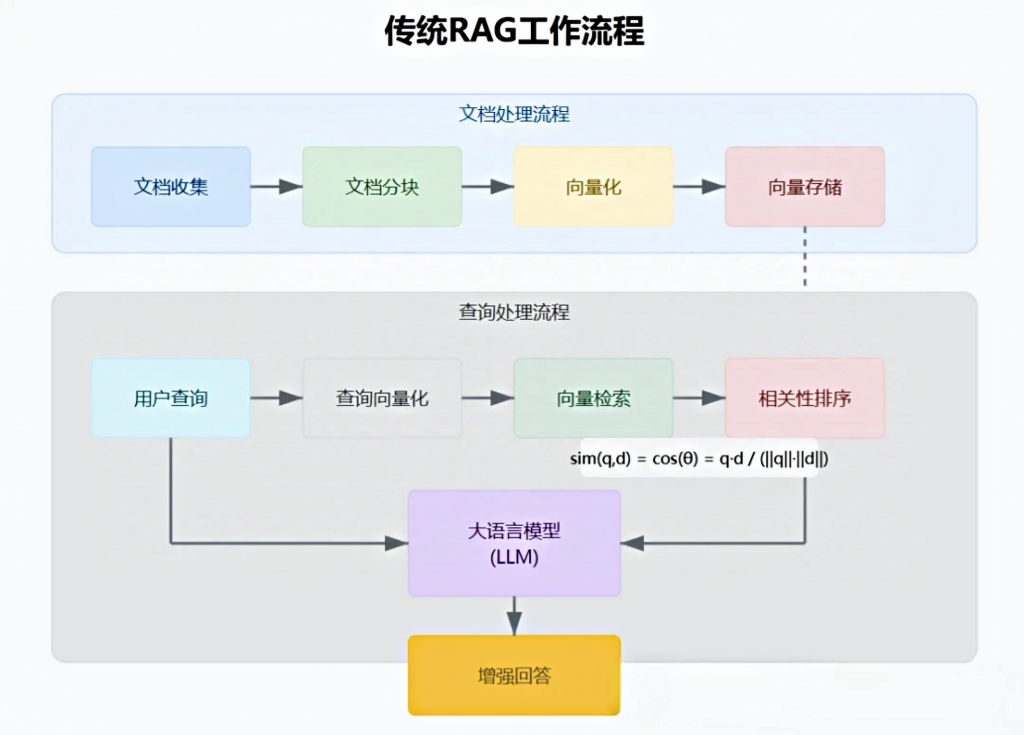
二、RAG架构
RAG架构通常分为三阶段:
结合检索内容与LLM预训练知识,生成连贯且上下文准确的回答。
三、RAG的核心优势
1.减少幻觉(Hallucination):通过检索真实数据约束生成内容,降低模型虚构信息的概率。
2.动态知识扩展:无需重新训练模型即可更新知识库,适应实时场景(如新闻、科技进展)。
3.领域适应性:通过定制知识库,快速应用于医疗、法律、金融等专业领域。
4.可解释性增强:生成结果附带检索来源,方便验证可信度。
四、典型应用场景
1.智能问答系统:回答需结合实时数据的问题(如“2023年诺贝尔奖得主是谁”)。
2.客服机器人:检索产品手册或政策文档,提供精准回复。
3.内容创作辅助:撰写文章时自动补充权威资料或统计数据。
4.教育领域:生成结合教材内容和最新研究的解析答案。
五、ChatWiki:RAG优化的“专家”
ChatWiki 是一款基于大语言模型(LLM)和检索增强生成(RAG)技术的开源知识库 AI 问答系统,支持企业快速构建私有化知识库助手,适用于客服、医疗、教育等场景。

1.多模态知识处理能力
- 支持导入 OFD、Word、Excel、PDF、Markdown 等格式文档,自动完成分块、向量化处理。
- 可整合网页、CSV 等数据源,并通过智能分段优化检索效果。
2.动态知识更新与低幻觉
- 支持实时更新知识库(如最新医疗指南或企业文档),无需重新训练模型。
- 通过检索结果约束生成逻辑,减少大模型虚构内容。
3.Graph RAG 增强推理
- 引入图数据库(Graph Database)技术,利用节点和边的关系提升多跳推理能力(例如通过实体关联链回答复杂问题)。
- 相较于传统 RAG 的孤立文本片段,可返回结构化关联信息,生成逻辑更完整的答案。
4.灵活部署与数据安全
- 支持纯本地私有化部署,保障企业数据隐私。
- 提供 Docker 部署、离线部署等多种方式,适配云端或本地环境46。
5.广泛模型支持与易用性
- 已集成 DeepSeek、OpenAI、Claude、文心一言、火山引擎等 20+ 国内外主流模型,配置简单(仅需配置 API key)。
- 可视化界面支持工作流编排,可组合大模型、工具和业务逻辑节点。开源地址
github地址:https://github.com/zhimaAi/chatwiki
了解更多功能详情,
获取功能试用,请扫码联系

原创文章,作者:小芝麻,如若转载,请注明出处:https://xiaokefu.com.cn/blog/26071.html
相关推荐
-
企微传统沟通 vs AI聊天工作流:效率差距有多大?
当企业微信成为连接内部协作与外部客户的核心枢纽,沟通效率直接决定企业运营的核心竞争力。 但现实中,多数企业仍深陷传统沟通的效率泥潭,而以芝麻微客为代表的…
-
售后红包怎么发?电商企业客服系统发售后红包教程
售后问题处理的及时性与合理性,往往是客户对品牌产生二次信任的转折点。售后红包的发放,不仅能快速弥补客户的不良购物体验,降低差评、投诉率,还能通过小额福利传递品牌温度,提升客户粘性与…
-
企业微信员工长时间未回复如何进行提醒?
企业微信客户消息漏回、回复不及时太影响服务体验了。 亲测用下面这个第三方应用工具的「未回复提醒」功能,就能轻松解决。点此进入芝麻微客官网 步骤如下: 新建规则:在「会话质检」→「未…
-
企微侧边栏发红包太方便了!欢迎语、群发都能配,还能限制领取次数
做企业运营的你,是不是总遇到这些难题:新客添加后留不住、老客互动没热情、群发消息石沉大海?点此进入芝麻小客服官网 别愁!今天给大家解锁企微红包的「隐藏玩法」 侧边栏一键发、多场景适…
-
如何利用企微AI工作流,实现“千人千面”的自动化逐客群发?
试想这样的场景: 当一位刚下载了你们App的新用户添加了企业微信,系统自动发送:“张先生,看到您刚刚体验了我们App的健身功能,这里有一份《办公室人群专…
-
未认证订阅号也能使用公众号渠道二维码了!
之前认证的订阅号才能使用渠道二维码功能,现在未认证订阅号也能使用渠道二维码功能了!只需要接入芝麻小客服后台就能使用,免费版有使用权限。点此进入芝麻小客服官网 渠道二维码的作用有哪些…
-
1 人顶 10 人!微信小店客服聚合系统,多店铺咨询一键整合
二、芝麻小客服聚合客服系统 1. 多店消息聚合 打破店铺壁垒,将所有微信小店的咨询、订单、售后信息集中整合到同一工作台。客服无需切换后台,实时接收多店消息,3 秒内即可响应客户。 …
-
什么是企业微信【会话存档】?会话存档的应用场景有哪些?
想象一下:销售精英如何精准拿下百万订单?金牌客服如何三言两语化解客户怒火?那些在企微聊天中无意泄露的商机或风险,是否都悄然消逝在信息流中?点此进入芝麻小…
-
视频号小店的分享员是什么?如何添加分享员?
视频号的分享员是基于商家低成本获客产生的,他们的主要任务是帮助商家去推广分享商品、视频号直播间等给好友,从而给品牌商家的视频号直播间带来流量,给自己带来相应的返利。 但是由于商家的…
-
企微直播是怎么玩的?客户评论直播后能自动给客户打上标签吗?
私域直播已经成为企业获客转化的标配,但很多运营者都会遇到这样的困惑:一场直播明明有几百人观看,却不知道谁看了、谁有意向,只能对着冷冰冰的“累计观看人数”干瞪眼。点此进入芝麻小客官网…
