

RAG,全称为 Retrieval-Augmented Generation,即检索增强生成。RAG 知识库的工作原理基于一个核心思想:当用户提出问题时,系统首先会在庞大的知识库中进行检索,寻找与问题相关的信息片段。
通过先进的算法和技术,RAG 能够从海量的文档、数据中快速筛选出最相关的内容,大大提高了信息获取的效率和准确性。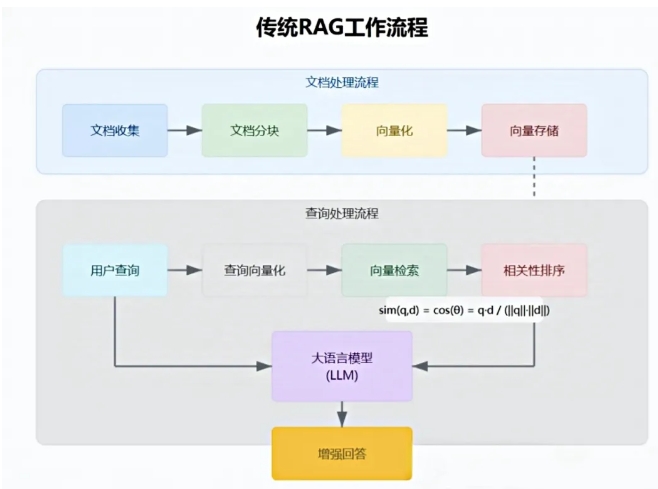 与传统的语言模型相比,RAG 知识库具有诸多显著优势。
与传统的语言模型相比,RAG 知识库具有诸多显著优势。
1.知识的时效性问题
传统语言模型往往依赖于预训练的数据,其知识储备相对固定,难以实时获取最新的信息。而 RAG 知识库则不同,它能够实时查询外部知识库,从而为用户提供更加及时、准确的回答。
当用户询问关于最新科技动态、时事新闻等问题时,RAG 能够迅速从最新的资讯中检索相关信息,给出最新的回答 ,这是传统模型难以企及的。
2.大模型的“幻觉”问题
RAG 知识库还能够有效减少模型的 “幻觉” 现象。所谓 “幻觉”,是指模型在生成回答时,可能会产生一些没有事实依据的内容。而 RAG 通过检索真实的信息片段,并基于这些片段生成回答,使得答案更加可靠,大大增强了用户对回答的信任度。
在医疗、金融等对准确性要求极高的领域,RAG 的这一优势显得尤为重要,能够为专业人士提供更加可靠的决策支持。
以ChatWiki平台为例,RAG知识库的构建可分为四大核心步骤,覆盖技术接入、数据处理、机器人配置到实际应用的全周期。
步骤1:接入AI大模型
RAG的“生成”环节依赖大模型的理解与输出能力,因此第一步需选择或接入适合企业需求的大模型。
ChatWiki支持对接GPT-4、Claude、DeepSeek、文心一言、火山引擎等20+国内外大模型,企业可根据响应速度、成本、功能需求灵活选择。
步骤2:创建知识库
知识库是大模型的“私有图书馆”,文档质量直接决定检索效果。ChatWiki支持批量上传PDF、Word、TXT等格式文件,并自动完成以下处理:
内容清洗:剔除重复页、广告页、乱码等无效内容;
语义分段:按章节、段落自动切分,生成带标签的知识片段(如“产品功能-支付模块”“售后政策-退换货流程”);
元数据标注:自动提取文档标题、创建时间、作者等信息,便于后续筛选与权限管理。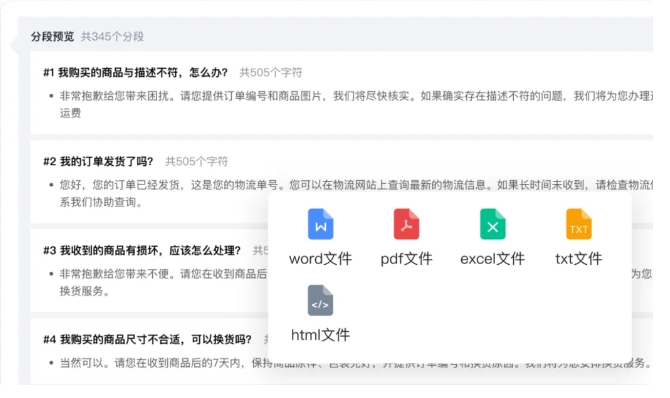 步骤3:创建AI机器人
步骤3:创建AI机器人
机器人是面向终端用户的交互入口。在ChatWiki中,企业需完成:
机器人基础配置:设置名称、头像、欢迎语(如“您好!我是XX智能客服,可解答产品、售后等问题”);
知识库关联:勾选目标知识库(支持多库联动,如同时关联“产品库”与“政策库”);
对话策略调优:设置“检索阈值”(仅返回相似度>80%的内容)、“回答长度限制”(避免冗长)、“未知问题话术”(当无匹配内容时,引导用户联系人工)。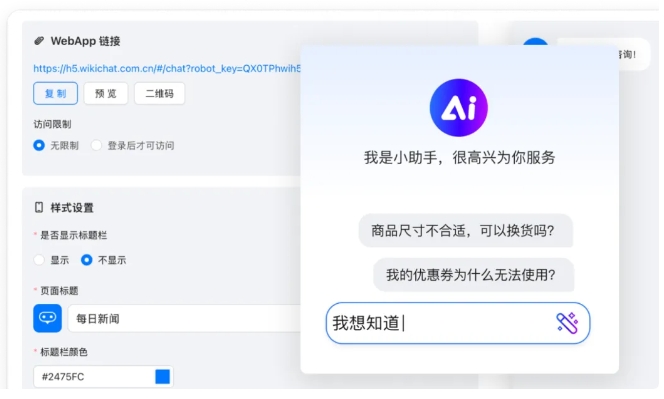 步骤4:客户咨询实战
步骤4:客户咨询实战
上线后,企业需通过真实用户咨询验证RAG系统的可靠性,并持续优化:
日志分析:通过ChatWiki后台查看“未命中问题”(用户提问但知识库无相关内容)、“踩回答”(用户评价“不满意”),针对性补充文档;
检索调优:若模型常检索到无关内容,可能是文档标签不准确,需人工修正元数据;若检索结果过少,可降低“检索阈值”或扩充同类文档;
模型微调:针对垂直场景(如技术术语解释),可上传企业内部术语表,通过微调让大模型更好理解专业词汇。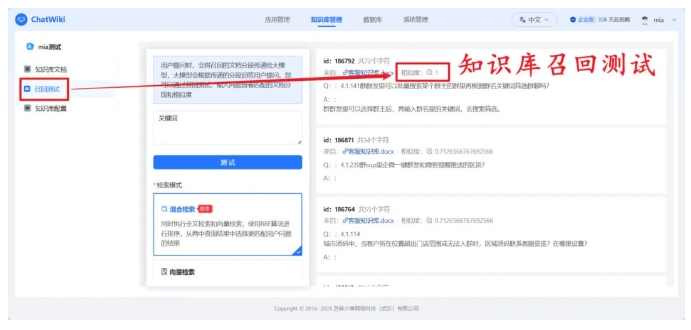 在AI时代,RAG知识库已从“可选工具”变为“企业刚需”。通过ChatWiki等平台的标准化流程,企业无需深度开发即可快速搭建专属智能问答系统,既保障了数据安全,又提升了服务效率。未来,随着大模型与RAG技术的融合深化,“更懂企业、更会说话”的智能知识库,将成为企业差异化竞争的核心壁垒。
在AI时代,RAG知识库已从“可选工具”变为“企业刚需”。通过ChatWiki等平台的标准化流程,企业无需深度开发即可快速搭建专属智能问答系统,既保障了数据安全,又提升了服务效率。未来,随着大模型与RAG技术的融合深化,“更懂企业、更会说话”的智能知识库,将成为企业差异化竞争的核心壁垒。
您有问题需要咨询的话,可以扫描下方二维码:

原创文章,作者:小芝麻,如若转载,请注明出处:https://xiaokefu.com.cn/blog/34902.html
相关推荐
-
这款“收款神器”火了!一码聚合微信+支付宝,关键是钱到账没有手续费!
点此进入支付宝/微信收款码在线制作 移动支付时代,微信、支付宝覆盖全场景,但商家同时用两者收款时,需展示两个收款码,顾客常困惑、商家需反复指引,交易低效。 而芝麻收款助手的 “收款…
-
万能收款码合并神器!支持微信&支付宝,3步教你用芝麻助手实现”一码收全款”
点此进入支付宝/微信收款码在线制作 对于商家而言,二合一万能收款码堪称运营管理的得力助手。以某条小吃街的一家烤串店为例,每到晚上就餐高峰期,店内座无虚席,店外还排起长队。过去,顾客…
-
公众号运营不费力!ChatWiki从写文到打理全拿捏
点此进入芝麻小客服官网 有没有人和我一样,手机里堆了一堆笔记、云盘存满各种文档,公众号干货刷到就收藏,结果越攒越乱?想找某份资料时,翻遍各个APP都找不到,手动整理又费时间,最后…
-
微信+支付宝收款码合并成“万能收款码”!不仅方便,关键提现免手续费!
点此进入支付宝/微信收款码在线制作 在移动支付普及的今天,微信和支付宝作为两大主流支付工具,几乎覆盖了所有消费场景。 然而,对于商家来说,同时展示两个收款码不仅占用空间,还可能让顾…
-
告别私信空白期!未认证公众号专属自动回复工具,秒回粉丝
点此进入芝麻小客服官网 微信公众平台对不同类型(订阅号/服务号)、不同认证状态的账号设置了差异化的功能权限。消息自动回复(用户发送任意消息时的自动回复) 被归类为“高级功能”,通…
-
手把手教你制作,微信+支付宝二合一万能收款码(免提现手续费)!
点此进入支付宝/微信收款码在线制作 微信支付宝二合一收款码是将微信与支付宝的收款码合并成一个的二维码。顾客扫码时,系统会自动识别其使用的支付软件并跳转,无需区分。通过芝麻收款助手生…
-
教你微信&支付宝收款码二合一,商家收款二维码一键生成合并!
点此进入支付宝/微信收款码在线制作 在这个数字化支付时代,微信和支付宝无疑是移动支付领域的领头羊。然而,它们各自的收款二维码却不能通用,这给许多商家带来了困扰。对于那些需要频繁收款…
-
万能收款码来了,微信 + 支付宝二合一,这款万能码真的不收提现手续费!
点此进入支付宝/微信收款码在线制作 在移动支付盛行的当下,微信与支付宝几乎成了每一位商家收款的 “标配”。然而,两个收款码并行的模式,却给日常收款带来了不少麻烦。顾客站在收款台…
-
万能收款码来了,微信 + 支付宝二合一,这款万能码真的不收提现手续费!
点此进入支付宝/微信收款码在线制作 在移动支付盛行的当下,微信与支付宝几乎成了每一位商家收款的 “标配”。然而,两个收款码并行的模式,却给日常收款带来了不少麻烦。顾客站在收款台前,…
-
发现了收款“神器”!一个二维码同时收微信+支付宝,还是免手续费的?
点此进入支付宝/微信收款码在线制作 在数字化支付普及的当下,不少商家都面临 “双码并存” 的困扰 —— 收银台贴着微信、支付宝两个收款码,顾客扫码时需来回切换软件,既耽误时间又影响…
