

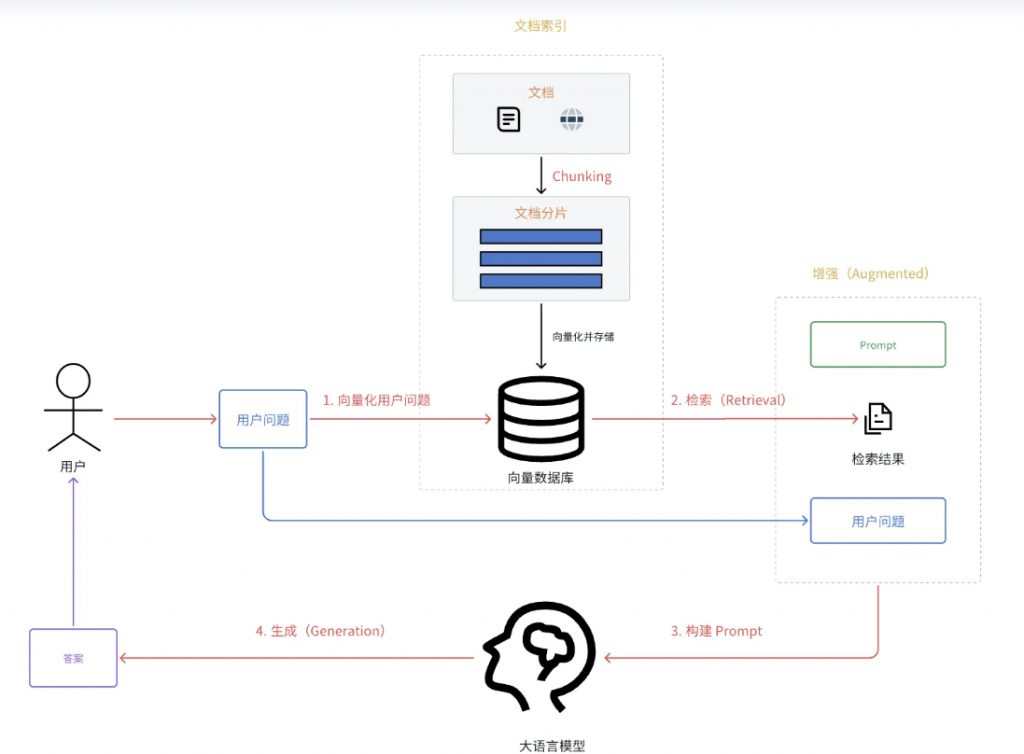
ChatWiki 的核心优势在于深度融合了大语言模型(LLM)、检索增强生成(RAG)与 GraphRAG 知识图谱三大核心技术,从根本上解决了传统知识库 “答非所问” 的痛点。点此进入chatwiki.官网
系统可将企业上传的文档自动抽取成知识图谱,通过向量与知识图谱的混合检索方式,大幅提升知识召回率,让 AI 能精准匹配用户问题与企业知识。
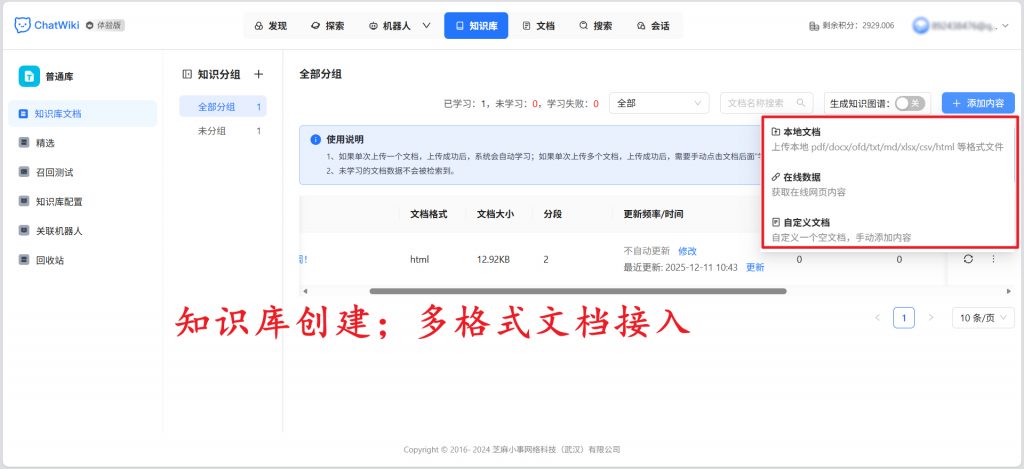
一、全格式兼容 + 智能预处理,零门槛完成知识沉淀
不仅如此,系统还提供自动化的数据预处理能力,支持智能分段、QA 分段、手动输入及 CSV 导入等多种方式,可根据文档内容自动完成文本切分、向量化或 QA 分割,同时支持自定义分段规则,适配不同企业的知识管理习惯。
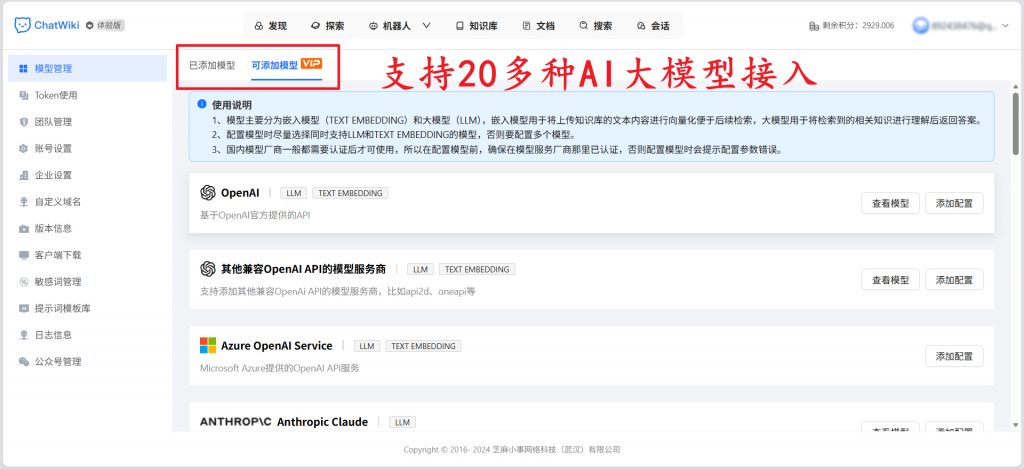
二、20 + 主流模型适配,企业按需选择无绑定
企业只需在系统后台简单配置模型 API Key 等参数,即可完成模型接入,且支持随时更换模型。
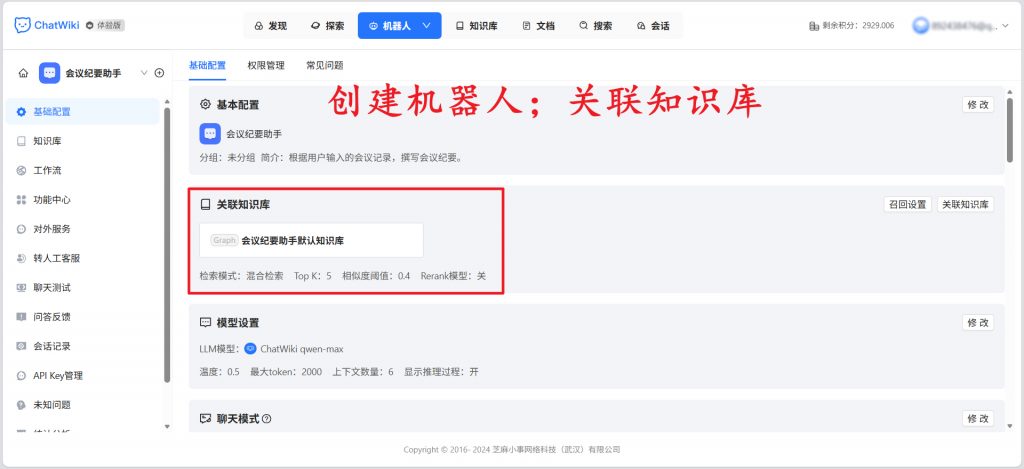
三、私有化部署,保障企业数据自主可控
同时,系统构建了多层安全防护机制,企业可根据岗位设置管理员、编辑员、只读成员等不同角色,实现敏感数据的分级管控。
四、多终端多场景覆盖,知识服务触达全链路
企业的知识使用场景遍布内部协作、客户服务、对外答疑等多个环节,单一的使用渠道无法满足全场景需求。
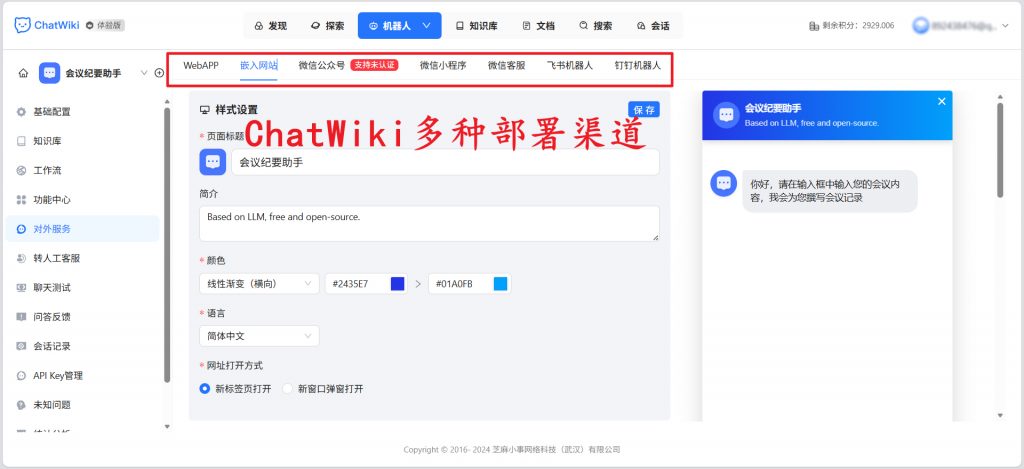
ChatWiki 打造了全渠道的知识服务能力,支持嵌入企业官网、桌面客户端、WebApp 等内部场景,也能对接微信公众号、微信小程序、微信客服外部客户服务渠道。
了解更多功能详情,
获取功能试用,请扫码联系
原创文章,作者:小芝麻,如若转载,请注明出处:https://xiaokefu.com.cn/blog/42350.html
相关推荐
-
24小时在线客服系统有什么功能?如何提高企业服务质量?
24小时在线客服系统不仅可以帮助企业高效处理客户问题,还能节省人力成本。 24小时客服系统有哪些功能呢? 首先就需要可以365天*24h在线,解决客户各类问题,这一点就需要客服系统…
-
企微【永久群活码】是如何生成的?群活码具体有什么作用?
在当今数字化营销的浪潮中,企业和商家都在积极探索高效的私域流量运营策略。而芝麻微客的【永久群活码】功能,正成为众多从业者手中的得力工具。点…
-
企微【会话存档】赋能教培行业:3招教你提高人效、执行力,破解管理痛点
在竞争激烈的教培行业,高效的管理是机构脱颖而出的关键。如今,众多教培机构面临着人效低下、执行力不足等难题,严重制约了机构的发…
-
芝麻小客服如何通过统计功能优化服务?
点此进入芝麻小客服官网 芝麻AI机器人为您提供了丰富的数据统计功能,以便您更好的提高机器人的使用效果。统计功能共分为三个部分:统计概览、转人工统计和历史会话。 一、统计概览 统计概…
-
RAG智能知识库机器人,让大模型更懂你的客户
传统的AI机器人使用LLM时,由于LLM的语言模式不是扎根知识进行训练的,所以很容易在接待客户中产生不准确或者会误导客户的陈述。而RAG检索增强生成技术,它可以通过额外的数据,为L…
-
怎么设置自动售后视频号里面的虚拟商品?
在视频号小店的商品栏中售卖的商品除了许多实物商品外,还有大量的虚拟商品,如果商家的小店突然爆单,或者虚拟商品出现不能用的问题该怎么办呢? 基本上每个商家都问过小芝麻这个问题,因此在…
-
智能客服系统如何实现便捷快速的沟通功能
点此进入芝麻小客服官网 1、全渠道接入我们的智能客服系统可覆盖企业全域场景,多元化的全媒体渠道融合让客服沟通更加方便快捷。 同时支持支持视频号小店/公众号/小程序/ H5 / PC…
-
芝麻微客会话存档,为虚拟服务企业筑起防私单、防飞单防火墙
点此进入芝麻小客服官网 某知名虚拟课程企业,专注于职业技能培训课程的线上销售与服务。经过多年发展,已积累了大量的学员资源,在行业内颇具影响力。但随着员工数量的增加和业务范围的拓展…
-
客服系统如何设置排队中自动接入
点此进入芝麻小客服官网 1. 客服上线时接入模式 自动从排队中接入; 客服手动选择从排队中接入人数,最大接入()人。 2. 自动接入数量 每次从排队中自动接入()人。 从排队中自动…
-
企微员工未及时回复客户?这套「超时提醒方案」兼顾隐私与效率
点此进入芝麻小客服官网 某金融机构在客户服务中遇到两大难题:既要保障企业微信聊天数据的隐私安全,又要避免员工因疏忽导致消息超时未回复。通过芝麻会话存档工具,其探索出一套「内网部署…
